

The landscape of real estate technology is undergoing a seismic shift, marking the definitive end of the era dominated by generic home search applications. For over a decade, the industry’s digital frontier was defined by platforms primarily focused on presenting property listings with photos and prices. However, the contemporary market is increasingly shaped by sophisticated investors, a demographic that requires far more than just a property browsing tool. They demand a comprehensive “decision engine” that empowers them to analyze, underwrite, and confidently invest. This pivotal transition from mere search to in-depth analysis presents a substantial opportunity for entrepreneurs and technology innovators to capture a high-value audience willing to invest in actionable data rather than merely consuming free content.
This comprehensive guide serves as a blueprint for developing a scalable and data-driven real estate investment application. It will delve into critical aspects including product strategy, technical architecture, and effective monetization models tailored for this evolving market. At its core, a successful real estate investment application necessitates a robust three-layered approach: a visual presentation layer, an inventory layer, and a crucial intelligence layer. The most accelerated path to market involves integrating pre-calculated investment data via APIs, allowing development teams to concentrate their engineering efforts on differentiation and unique feature development rather than the time-consuming and resource-intensive task of data cleaning and normalization.
The Strategic Pivot: Why Investment-Grade Intelligence Wins in PropTech
The majority of real estate technology startups falter due to a misguided attempt to compete directly with established giants like Zillow on inventory. This is an unwinnable battle, given Zillow’s extensive MLS contracts and billions in funding. Instead, the most successful PropTech ventures are carving out significant market share by prioritizing financial intelligence. While a generic application might display a three-bedroom house at a specific price point, an investment-grade platform offers a more nuanced perspective: the same three-bedroom house might be presented with a compelling 7.8% Cap Rate and an estimated $3,200 in potential monthly Airbnb revenue.
The fundamental objective of such platforms is not to help users find a house, but rather to empower them to underwrite a real estate asset effectively. This strategic reorientation transforms the application’s backend from a passive display of information into an active, analytical tool for financial decision-making. This shift is underscored by the increasing demand for granular financial metrics, a trend driven by both individual investors seeking to maximize returns and institutional players requiring sophisticated analytical capabilities.
Core Features for an Investor-Centric Application
To build an application that resonates deeply with real estate investors, developers must transcend basic search filters such as the number of bedrooms and bathrooms. The core features must directly address the paramount question: "Will this property generate a profitable return?"
ROI-Driven Search Capabilities
Investors do not typically search by school district or proximity to parks. Their primary filter is yield. Therefore, an investment application must incorporate filters that enable users to discover properties based on their financial performance. This includes the ability to sort and filter by metrics such as Capitalization Rate (Cap Rate), Cash-on-Cash Return, and projected Occupancy rates. This approach inverts the traditional search experience. Instead of starting with a location and hoping to find a suitable deal, users begin with a profit goal and identify the locations that best align with their financial objectives. This data-driven approach allows for a more targeted and efficient investment process.
Interactive Heatmaps for Visualizing Investment Corridors
The sheer volume of property data can be overwhelming for human comprehension. A list of hundreds of properties, each with numerous data points, is difficult to parse effectively. The solution lies in visual intelligence. The strategic use of heatmaps can effectively visualize “Investable Corridors,” highlighting areas with high potential. By overlaying profitability layers onto a map, users can instantly identify neighborhoods offering the highest Airbnb revenue potential or the lowest price-to-rent ratios. This visual discovery layer often serves as the initial engagement point, drawing users into the platform and guiding their exploration towards promising opportunities. The ability to visually assess market potential at a glance significantly accelerates the initial due diligence phase.
The Deal Analyzer: A Critical Retention Tool
The Deal Analyzer serves as the primary retention hook for an investment application. Once a user identifies a potential property, they need a robust tool to run the numbers accurately. A dynamic calculator should allow users to toggle between traditional rental income strategies and short-term rental (Airbnb) strategies to determine which approach yields a superior return. The key to a truly effective analyzer lies in its customization. Static, default values are insufficient. Users must be able to input their specific mortgage rates, management fees, property taxes, insurance costs, and down payment percentages to observe how the Cash-on-Cash return and other key metrics fluctuate based on their unique financial situation. This level of personalization fosters trust and provides a realistic projection of potential outcomes.
The Data Ecosystem: Understanding the Essential Stack
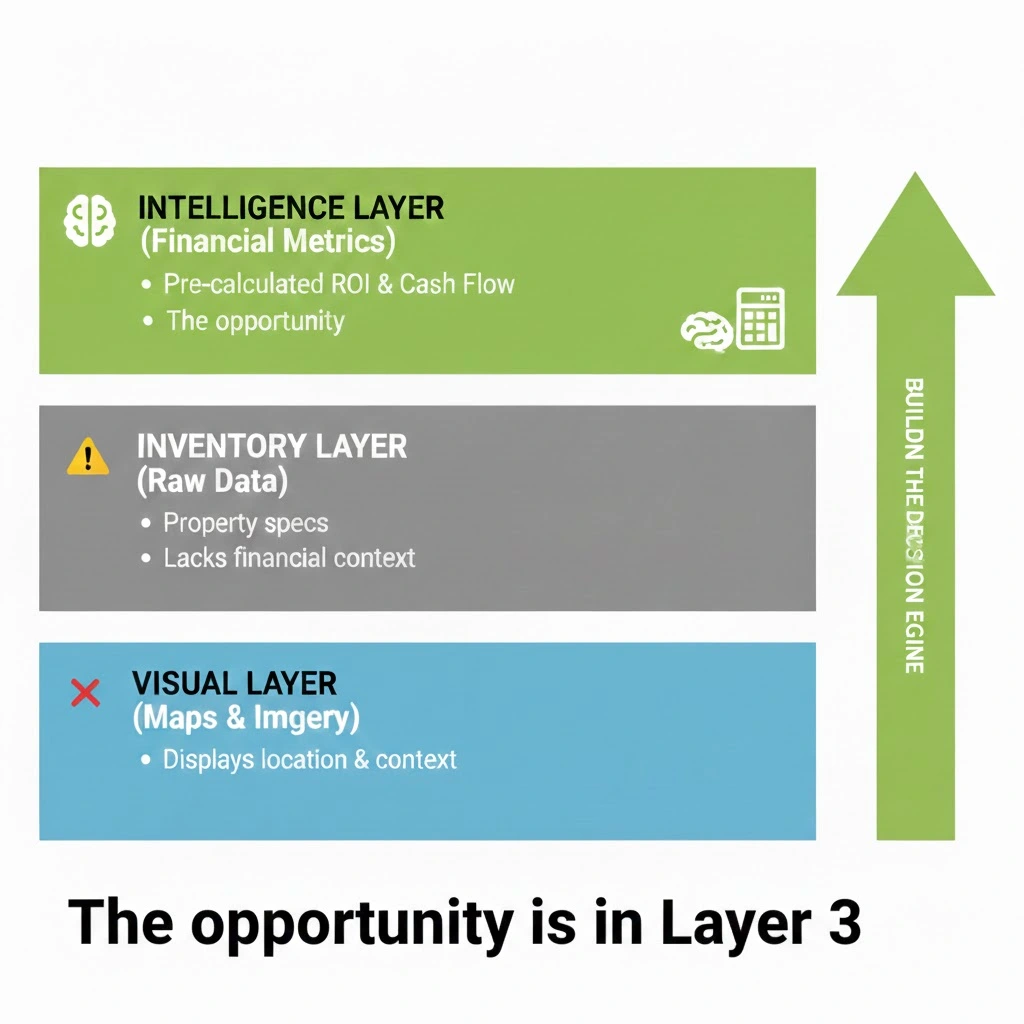
Before any lines of code are written, a thorough understanding of the real estate data landscape is paramount. Many founders mistakenly assume that all real estate data is homogenous, a critical error that can lead to project failure. A modern, high-performance real estate application is, in essence, a sophisticated stack comprising three distinct types of APIs.
Type A: The Visual Layer APIs
These are the foundational, often commoditized APIs, such as Google Maps or Mapbox. While essential for displaying property locations and providing street-level views, they are inherently limited in their valuation capabilities. They can indicate a property’s proximity to amenities like parks but cannot quantify how that proximity influences rental yield or property appreciation.
Type B: The Inventory Layer APIs
This layer provides the raw listing data, including addresses, square footage, number of rooms, and list prices. While indispensable, this data is fundamentally incomplete for serious investors. It confirms the existence of a property but offers little insight into its financial viability. Solely relying on this layer necessitates the establishment of extensive internal teams dedicated to data cleaning, normalization, and enrichment, a costly and time-consuming undertaking.

Type C: The Intelligence Layer APIs
This is the crucial missing link where a significant percentage of real estate applications fall short. To construct a truly valuable investment platform, access to pre-calculated financial metrics is essential. This includes reliable data on rental comparables, expense ratios, historical occupancy rates, and projected returns for specific properties. Building this comprehensive dataset from scratch is an arduous process, often requiring years of dedicated engineering effort and substantial investment. Many founders find themselves stalled at this stage, possessing the visual and inventory data but lacking the sophisticated investment logic and pre-computed analytics.
The Master Architecture: A Top-to-Bottom View for Scalability
To develop a high-performance real estate investment engine, it is imperative to move beyond a rudimentary client-server model. A production-ready architecture demands a three-tiered approach that effectively separates raw data ingestion from proprietary investment logic. This structured design ensures that the application functions not merely as a data viewer but as a sophisticated financial analysis tool.
Tier 1: The Ingestion Tier (Data Sourcing and Aggregation)
This forms the bedrock of the application’s data architecture. Rather than relying on fragile web scraping techniques, the optimal approach is to ingest pre-normalized data through robust, infrastructure-grade APIs. This ensures data accuracy, consistency, and timely updates, minimizing the risk of data corruption or outdated information.
Tier 2: The Logic Engine Tier (The Proprietary Value Proposition)
This middle layer is where the application adds its unique, proprietary value. It acts as an intermediary between the raw data provided by APIs and the user interface. This tier is responsible for performing the "user-context overlay," taking baseline API data and recalculating it based on user-specific inputs and preferences. This dynamic analysis is what transforms generic data into personalized investment insights.
Tier 3: The Presentation Tier (The User Interface and Experience)
The apex of the architectural stack is where the product vision is realized and delivered to the end-user. This tier focuses on creating an intuitive, visually appealing, and highly functional user interface that allows investors to easily interact with the complex data and analytical tools provided by the underlying layers.
The Request Lifecycle: From User Click to Financial Insight
To fully grasp the interplay between these architectural tiers in a live environment, understanding the procedural execution flow of a single user session is crucial. This sequence of events, often referred to as the “data ladder,” transforms raw data into actionable financial decisions:
- User Initiates Request: A user interacts with the application’s interface, triggering a specific data request (e.g., searching for properties in a particular area, analyzing a specific listing).
- Presentation Tier Communicates: The frontend (Presentation Tier) translates the user’s action into a structured API request to the backend.
- Ingestion Tier Fetches Data: The backend’s Ingestion Tier receives the request and queries the relevant external data APIs (Type A, B, and C) to retrieve the necessary raw and pre-calculated data.
- Logic Engine Processes Data: The raw data is then passed to the Logic Engine Tier. Here, proprietary algorithms and user-specific parameters are applied to perform in-depth analysis, recalculations, and scenario modeling.
- Data Flows Back: The processed and enriched data is sent back from the Logic Engine to the Presentation Tier.
- User Receives Insight: The frontend formats and displays the final, actionable insights to the user in a clear and understandable manner, facilitating informed decision-making.
The Architecture Solution: Leveraging Infrastructure-Grade APIs
Historically, the primary barrier to entry for building sophisticated real estate investment applications was the data pipeline. This required substantial investment in data engineering teams to scrape websites, meticulously clean addresses, and deduplicate records. Fortunately, the advent of infrastructure-grade APIs has significantly democratized this process. These APIs now handle the complexities of the Intelligence Layer, effectively bypassing the need for extensive internal data infrastructure development.
To illustrate a lean and efficient build process, we can reference the Mashvisor API as a model implementation. This API is particularly noteworthy as it uniquely combines the Inventory Layer with the Intelligence Layer directly. It provides pre-calculated investment metrics, such as Cap Rate and Cash-on-Cash Return, which are fundamental components of the architecture being designed.
Accelerating Development with Integrated Data APIs
A well-designed backend architecture for a real estate investment application should be segmented into three distinct tiers of data ingestion. This tripartite structure is fundamental to ensuring the application is not only fast and accurate but also highly scalable and adaptable to future market demands.
Tier 1: The Market Benchmark Layer
Before a user delves into specific property details, they often begin by evaluating the broader market landscape. Building a backend system capable of aggregating thousands of individual listings to derive median performance metrics can be computationally intensive and lead to slow loading times. The architectural solution to this challenge lies in targeting summary endpoints. Instead of performing local aggregations, the ingestion layer should query endpoints that provide normalized market benchmarks. For example, a single request to an endpoint like GET /v1.1/client/city/investment can return key metrics such as airbnb_cap_rate, traditional_rental_income, and occupancy rates for an entire city. This enables the frontend to render market health dashboards almost instantaneously, without placing undue strain on the application’s database.
This market benchmark layer is particularly critical for the effective implementation of the heatmap feature discussed earlier. By fetching these city-level averages, the application can dynamically color-code neighborhoods based on their performance metrics, visually guiding users toward the most profitable areas before they even select a specific listing. This proactive guidance significantly enhances user engagement and efficiency.

Tier 2: The Property Object and Financial Core
This tier represents the heart of the application’s analytical capabilities. While a standard Multiple Listing Service (MLS) feed provides essential physical characteristics of a property, an investment-grade API delivers the crucial financial performance data. The system should be designed to utilize a unified endpoint, such as GET https://api.mashvisor.com/v1.1/client/property. This endpoint acts as a universal access point, allowing users to retrieve property data using various identifiers, including Street Address, Mashvisor ID, or MLS ID, ensuring maximum flexibility regardless of how a deal is discovered. By submitting query parameters like address, city, state, and zip_code, the system triggers a request that returns far more than just a list price.
The response includes a detailed breakdown object containing pre-calculated metrics for cash_flow, cap_rate, and rental_income for both Airbnb and Traditional rental strategies presented side-by-side. By ingesting this comprehensive object, the investment logic engine begins with a complete underwriting model rather than an incomplete dataset. This empowers developers to focus on building proprietary features, such as custom expense modeling and advanced scenario planning, rather than expending resources on fundamental financial calculations. The distinction between raw data and investment intelligence becomes evident in the JSON response from such an API:
"mls_id": "937135",
"ROI":
"traditional_rental": 1835,
"airbnb_rental": 397,
"traditional_cap_rate": 1.81,
"airbnb_cap_rate": -2.69,
"roi_updated_at": "2026-01-25T08:09:11.000Z"
,
"neighborhood":
"name": "Little Bit of Country",
"mashMeter": 29
This approach mitigates the significant risk associated with internal calculation errors, which can erode user trust. While an MLS feed provides physical specifications, an intelligence-grade API delivers the foundational underwriting data.
Tier 3: The Validation Layer
Trust in financial projections is built upon verifiable evidence. Users will be hesitant to accept ROI projections unless they can readily access the comparable properties and aggregated data that underpin those calculations. To establish a robust “Validation Layer,” an application’s architecture should integrate two synchronized endpoints:
1. Macro: Aggregated Analysis
The GET /v1.1/client/rento-calculator/lookup endpoint is instrumental in establishing the market baseline for analysis. This serves as the engine for high-level financial projections. Because it operates dynamically across multiple geographical levels—including City, Neighborhood, Zip Code, or a specific Street Address—it enables the application to return pre-modeled financial metrics such as median rental income, occupancy rates, and cap rates in a single, efficient call.
2. Micro: Dynamic Evidence
To anchor these high-level projections in tangible reality, the GET/v1.1/client/rento-calculator/list-comps endpoint should be layered in. This endpoint retrieves the actual Airbnb or Long-Term Rental (LTR) properties that were used in the macro analysis. This provides granular, real-world data that supports the aggregated findings.
The "Macro-to-Micro" Advantage creates a seamless trust loop by pairing high-level projections with granular, verifiable evidence. By utilizing these synchronized rento-calculator endpoints, developers can deliver dynamic, street-level validation through a unified data structure, significantly boosting both investor confidence and engineering efficiency.
The Logic Engine: Elevating Beyond Basic API Integration
While APIs serve as the raw fuel for the application, the Logic Engine is the true driving force. The most critical component of a custom architecture is the investment logic engine itself. This is the proprietary code that differentiates the platform from a mere data viewer. A common pitfall for many founders is tightly coupling their frontend directly to the API response, displaying raw fields like airbnb_cash_flow without further analysis. This represents a missed opportunity to add significant value. A production-grade architecture treats the API response as a baseline scenario, a starting point for more sophisticated analysis.
Implementing the User Context Overlay
The investment logic engine should ingest these baseline values and then apply a “user context overlay.” This overlay encompasses user-specific variables such as financing terms, personal tax brackets, and preferred management strategies. For instance, an API might return a Cap Rate calculated based on an all-cash purchase. The application’s engine should then be capable of taking that Net Operating Income (NOI) and dynamically calculating a Leveraged Internal Rate of Return (IRR), factoring in current mortgage rates and other debt servicing costs. This necessitates a stateless calculation service positioned between the normalized data and the frontend.
Consider a property in Florida with a baseline IRR of 11% assuming an all-cash purchase. If a user then utilizes a financing toggle to apply a 25% down payment with a 6.8% mortgage rate, the engine should instantaneously recalculate that IRR to 17.4%, accurately accounting for the new debt service obligations. This immediate transition from raw data to personalized insight is precisely why users are willing to pay for premium subscriptions. This transformation constitutes the core intellectual property of the software asset. The logic engine ingests the baseline "all-cash" data and outputs the "leveraged" reality:
"baseline_irr": 0.11,
"personalized_irr": 0.174,
"user_context": "down_payment": 0.25, "interest_rate": 0.068 ,
"monthly_debt_service": 2150
By developing this sophisticated logic layer, the application becomes insulated from the direct dependencies of external data sources. Should an API provider change its data structure or endpoints, the proprietary algorithms for calculating IRR and other key metrics remain intact as valuable intellectual property. This clear separation of concerns is vital for long-term scalability and the overall valuation of the software asset.
Solving Seasonality with Advanced Historical Data Analysis
One of the most significant challenges in real estate engineering is accurately accounting for seasonality. A simple snapshot of current rental income can be dangerously misleading. For example, a property in a popular beach town might show zero revenue in November but generate $15,000 in July. If an application only ingests current-month performance data, it will provide a wildly inaccurate underwriting model.
To effectively address this complexity, the application’s architecture must implement a Time Series Analysis Layer. This layer interacts with historical performance endpoints to retrieve trend data spanning the last 12 to 36 months. When querying Historical Performance endpoints, the system receives a dataset detailing monthly occupancy rates, average daily rates, and revenue figures. The architecture should not merely display this data as a chart; it must ingest this time-series data to compute a Seasonality Index for the property. By analyzing the month-over-month variance in occupancy and revenue, the system can assign a Risk Score to the asset. A property with consistent revenue throughout the year is low-risk, whereas a property exhibiting high variance between peak and off-peak seasons is high-risk. Presenting this calculated risk score to users adds substantial, actionable value. This analysis of historical data can lead to insights such as:
"property_id": "12345",
"monthly_historical": [
"month": "July", "rev": 8200, "occ": 0.94,
"month": "Nov", "rev": 1200, "occ": 0.18
],
"calculated_risk_index": "High (Seasonal)"
The Build vs. Buy Financial Argument: A Strategic Decision
The decision to architect a real estate investment application around an established API, such as Mashvisor’s, is fundamentally a financial one. The alternative—building an in-house data engineering division—represents a substantial and ongoing financial commitment, easily exceeding $150,000 per year in engineering salaries and infrastructure costs alone.
To effectively visualize the trade-offs between engineering overhead and speed-to-market, consider the following comparative analysis:
| Feature | Build Internally | Integrate API |
|---|---|---|
| Time to Market | 6-12 months | 2-4 weeks |
| Engineering | Dedicated Data Team required | Existing Backend team |
| Maintenance | Constant scraper updates, data validation | Managed endpoints, vendor support |
| Legal/Risk | High legal risk (e.g., data scraping compliance) | Fully licensed, compliant data source |
| Pricing | High/Unpredictable Capital Expenditure (Capex) | Fixed/Scalable Operational Expenditure (Opex) |
By adopting a "Buy" mindset for data infrastructure, real estate entrepreneurs can treat real estate data as a utility. This strategic shift liberates internal teams to concentrate on core competencies:
- Developing Proprietary Algorithms: Focusing on unique financial modeling and analytical features.
- Enhancing User Experience: Creating intuitive interfaces and seamless user workflows.
- Driving Product Innovation: Building advanced features that differentiate the platform.
- Scaling the Business: Concentrating on growth and market penetration.
Monetizing the Intelligence Layer: Selling Certainty Over Information
Generic real estate applications often struggle with effective monetization strategies because property search has become largely commoditized. Investment platforms, however, possess powerful revenue levers because they sell financial certainty and actionable insights. The monetization strategy should directly mirror the application’s data architecture.
The Pro Subscription: Gating the Intelligence Layer
The most effective monetization model is a value-based paywall. The visual layer (maps) and the inventory layer (listing specifications) can be used to drive top-of-funnel engagement and encourage user sign-ups. However, once a user attempts to access the critical intelligence layer—comprising pre-calculated Cap Rates, Cash-on-Cash Returns, and the logic-engine-driven calculators—they are prompted to upgrade to a Pro Tier. By gating these Mashvisor-powered financial objects, revenue generation becomes directly tied to the highest-value data points within the application’s stack.
The Enterprise Tier: The Validation and Risk Premium
For institutional investors and high-volume buyers, achieving a high level of trust necessitates access to comprehensive documentation and validation. The "validation layer," which provides granular evidence for projections, can be monetized separately. This tier offers access to:
- Detailed Comparable Property Reports: In-depth analysis of similar properties used for valuation.
- Aggregated Market Data: Comprehensive reports on neighborhood and city-level performance trends.
- Customizable Underwriting Templates: Tools for institutional clients to integrate their specific reporting requirements.
- API Access for Bulk Data: Providing programmatic access to data for large-scale analysis.
The High-Intent Lead Generation Model
Instead of selling generic leads to any real estate agent, platforms can strategically route "Investment-Ready" leads. A user who has spent significant time adjusting mortgage rate sliders within the logic engine, fine-tuning their investment parameters, is a high-intent buyer. By tagging users based on the specific ROI thresholds they are targeting, platforms can connect them with investment-savvy realtors or lenders who are willing to pay a premium for qualified, data-driven prospects. This creates a valuable ecosystem where investors, service providers, and the platform itself benefit.
Conclusion: The Future is Intelligent, Data-Driven Investment
The prevailing opportunity within the PropTech sector today lies not in sheer volume of listings, but in the depth and value of the insights provided. By strategically pivoting from a generic search portal to a specialized Investment Platform, entrepreneurs can address a more challenging problem for a more lucrative audience.
With the right architectural foundation, anchored by robust data APIs like Mashvisor’s, it is entirely feasible to build a product that transcends simply showing users a house. Such a platform can illuminate their potential financial future, providing the clarity and confidence needed for informed investment decisions. Technology is no longer the primary barrier to entry; the tools and infrastructure exist to develop these sophisticated applications within months rather than years. The ultimate determinant of success now rests on astute execution and strategic vision.
Ready to Build the Next Generation of PropTech?
Don’t allow data fragmentation to impede your launch timeline. Join the growing cohort of forward-thinking founders and developers who are leveraging Mashvisor’s infrastructure-grade API to power their cutting-edge real estate investment engines.
Book a short introductory call to collaboratively map out your ideal architecture and data stack.


